
DevEx^AI: An Agent-Readiness Framework
A Framework for Measuring AI Automation Maturity Across the Product Development Lifecycle
Executive Summary
The next phase of AI in software engineering is not about writing more code faster. It is about reducing friction across every stage of how software is built, validated, shipped, and measured so that developers and their agents can do their best work together.
DevExAI ™ is a framework for measuring and improving agent-readiness across the entire product development lifecycle. Most engineering organizations have achieved the first milestone: AI literacy. Engineers use assistants and AI is part of daily work. The opportunity now is to move beyond AI-assisted code generation and enable AI agents to operate effectively across every stage of how software is built.
The thesis is simple: the same things that block AI agents block developers. Code production has never been the primary bottleneck in mature software organizations. The friction is in everything else—specifications, test infrastructure, review processes, documentation, feedback loops. When you reduce that friction for agents, you reduce it for everyone.
The framework organizes 10 stages of the product development lifecycle into 5 domains, each scored on a 0–4 agent-readiness scale. This produces a scorecard and spider chart that gives engineering leadership immediate visibility into where automation is advancing, where it is stalled, and where investment will have the greatest impact. The unit of progress is not AI usage, it is agent enablement, through the removal of friction.
Critically, DevExAI keeps the developer at the center. The “raised to the power of AI” formulation is intentional: the base is developer experience, AI is the exponent. The Agent-Ready Maturity Model measures infrastructure readiness; traditional developer experience surveys and operational metrics like DORA remain essential companions that ensure infrastructure progress translates into real human outcomes.
The Core Thesis: DevExAI
Developer Experience raised to the power of AI.
AI has opened something remarkable for software engineering. The volume of implementation work a single engineer can produce has increased dramatically. Agents draft implementations, generate tests, and write documentation. The capability is real, it is improving rapidly, and it changes the calculus of how software gets built.
The opportunity, and it is an enormous one, extends far beyond code generation. Every stage of the product development lifecycle can benefit from AI and agent involvement. The teams that capture the full value of this moment will be the ones that enable agents across the entire lifecycle, not just in the editor.
There is a growing conversation about whether the traditional software development lifecycle is being redefined. As agents compress the boundaries between stages—requirements flowing into implementation, testing happening alongside code generation, deployment becoming continuous and automatic—the discrete, sequential model many teams operate on is evolving. In time, the lifecycle may look fundamentally different from the one we know today.
But for established software companies with customers, compliance obligations, institutional knowledge, and teams that coordinate at scale, the SDLC still represents how work gets done. The stages may become more fluid, the boundaries less rigid, but the underlying work—understanding what to build, building it correctly, proving it works, shipping it safely, and learning whether it delivered value—does not disappear. It is the work of building reliable, maintainable software that drives the current software industry.
This framework is designed to meet those teams where they are. Not by measuring AI adoption, but by providing a structured approach to moving each stage of the lifecycle from manual to AI-assisted to agent-enabled. The goal is not to dismantle the lifecycle but to systematically reduce the friction within it so that both humans and agents can operate at maximum effectiveness.
Outputting code has never guaranteed successful software. The DevOps and Developer Experience movements were built on this understanding: the hardest challenges in scaling a successful product are rarely in code generation itself. They are in the coordination, security, quality, feedback, and delivery systems that surround it. The industry’s most impactful investments—CI/CD, testing infrastructure, observability, developer tooling—have always targeted friction across the full lifecycle, not code output. That is why improving these systems has been recognized as one of the most critical levers of success for great software companies.
That principle does not change with AI. It becomes more urgent. As implementation speed increases, the quality of every other stage—discovery, specification, testing, review, documentation, observability, feedback—becomes the primary differentiator between teams that deliver value and teams that simply deliver code faster.
That is what DevExAI is about. It is not about AI writing code. It is about enabling developers WITH their agents, end to end.
From Adoption to Enablement
Successful AI adoption started with getting people to use AI at all; building literacy and making it part of daily work. That was step one and many companies have achieved this level. The next phase is harder and much more consequential.
The teams that thrive with AI will not be the ones where individuals use AI coding assistants most frequently. They will be the ones that enable agents throughout the software lifecycle. The way to drive that is by measuring what level of agent-readiness is attained within each stage, within each domain; not measuring how much people are using AI, but how much the organization is reducing the friction that allows agents to deliver maximum value.
DevExAI provides the measurement framework. It enables teams to see where they are today, establish time-bound goals, and track progress stage by stage. The unit of progress is not “AI usage”, it is “friction removed.”
The Win-Win: What’s Good for Agents Is Good for Developers
There is an elegant symmetry at the heart of this framework: an experience that is great for agents is also an experience that is great for developers.
One of the historical challenges with DevEx improvements is that humans are remarkably adaptable. Teams institutionalize friction. They build workarounds, develop tribal knowledge, and normalize manual processes to the point where the value of improving feels like it isn’t worth the cost of change. The pain is real but diffuse, so it persists.
Agents are not as creative about finding ways past friction or rationalizing why it’s acceptable. An agent can’t rely on tribal knowledge. It can’t “just ask Sarah” how the deploy process works. It can’t compensate for a missing test suite by being extra careful. When an agent hits a wall, the wall is visible; a concrete, measurable, blocker.
This is what makes agents such powerful catalysts for improvement. Because they cannot work around friction the way humans have learned to, they make the friction visible. And visible friction is friction that can be addressed. Optimizing for agents forces the kind of infrastructure investment that benefits everyone. Better specifications, better test coverage, better documentation, clearer architectural patterns – improvements compound for agents and developers alike.
DevExAI is a win-win by construction: every investment in agent-readiness pays dividends in developer experience.
Maturity Levels
Each stage of the product development lifecycle is scored on a five-level scale reflecting the degree to which an AI agent can participate in that work:

The goal is not to reach Level 4 everywhere. The goal is to know where you are at each stage, identify what’s blocking the next level, and make deliberate progress. Some stages may remain human-led by design. Others should be as automated as possible.
The Five Domains
The 10 stages of the product development lifecycle group into five composite domains. Each domain represents a distinct phase of value creation, from understanding what to build through learning whether it worked. Each stage includes an agent-ready vision: a concrete picture of what that stage looks like when the infrastructure, processes, and tooling are in place for agents to operate effectively alongside developers.
Domain: DEFINE
Understand the problem and plan the work
The Define domain covers everything from identifying what to build through breaking it into actionable units of work. This is where human judgment has the highest leverage—and where the quality of AI output across all downstream stages is determined. Spec-driven development, context engineering, and disciplined work decomposition are the foundation of effective agent collaboration.
Stage 1: Problem Discovery & Prioritization
Customer needs are identified, validated, and prioritized. Includes feedback intake, market analysis, support ticket patterns, and roadmap decisions.
Output: a prioritized problem worth solving.
Agent-Ready vision: An agent surfaces relevant support tickets, usage patterns, and customer feedback when a team is planning work—reducing the time from “customers are struggling” to “we know what to build.”
Stage 2: Requirements & Specification
The problem is translated into what we’re building. Includes product specs, acceptance criteria, design mockups, architectural constraints, and machine-readable context.
Output: a spec that both humans and agents can act on.
Agent-Ready vision: Given a problem statement and context, an agent drafts a spec with acceptance criteria that a product manager refines rather than writes from scratch. Context is structured so that downstream agents can consume it directly.
Stage 3: Work Decomposition & Planning
The specification is broken into small, implementable units of work. Includes task breakdown, dependency mapping, sprint planning, and assignment.
Output: tickets that are clear, scoped, and ready for agent or human execution.
Agent-Ready vision: An agent decomposes a spec into well-scoped tickets with clear descriptions, dependencies mapped, and estimated complexity—ready for a lead to review and adjust.
Domain: BUILD
Write the code
The Build domain is where most AI adoption efforts have focused to date. Code generation via copilots and agents is the most visible application of AI in software engineering. While essential, it represents only one of ten stages—and its effectiveness is largely determined by the quality of the Define stage that precedes it.
Stage 4: Implementation
Code is written. Includes feature development, bug fixes, refactoring, and integration with existing systems. Ranges from copilot-assisted coding to fully agent-driven implementation from spec.
Output: a working branch with code changes.
Agent-Ready vision: Given a well-defined ticket and codebase context, an agent produces a working implementation that follows existing patterns, handles edge cases, and is ready for review. The agent operates within repo-aware guardrails that enforce style, security, and architectural standards.
Domain: VALIDATE
Prove the work is correct and safe
The Validate domain ensures that what was built actually works, meets quality and security standards, and aligns with architectural direction. Testing and code review serve different purposes and have different automation profiles. Industry consensus is clear: agents plus guardrails, not agents alone.
Stage 5: Testing & Quality Gates
Code is verified for correctness, security, and compliance. Includes automated unit tests, integration tests, end-to-end tests, regression suites, static application security testing (SAST), dependency vulnerability scanning, compliance policy checks, linting, static analysis, type checking, coverage thresholds, and architectural conformance checks. This stage encompasses both the creative work of writing good tests and the deterministic work of running automated quality gates.
Output: confidence that the change does what it should, doesn’t break what it shouldn’t, meets security and compliance standards, and passes all automated quality gates.
Agent-Ready vision: An agent generates comprehensive tests—unit, integration, and edge cases—aligned with existing patterns. Automated security scanning, compliance checks, linting, and static analysis run as deterministic gates. An agent interprets gate failures and proposes fixes without human triage.
Stage 6: Code Review & Knowledge Transfer
Changes are reviewed for code quality, business logic correctness, security posture, maintainability, and architectural alignment. Includes peer review of pull requests, verification that the change fulfills the intended business functionality, assessment of code readability and long-term maintainability, identification of security anti-patterns, feedback loops, and documentation of design decisions. This stage serves a dual purpose: catching issues that automated gates miss and transferring knowledge across the team.
Output: approved, merge-ready code with shared understanding of the design intent and trade-offs.
Agent-Ready vision: An agent performs a structured first-pass review covering pattern consistency, security anti-patterns, maintainability concerns, and business logic alignment with the ticket spec. Human reviewers focus on architectural judgment, design trade-offs, and knowledge sharing—the parts that require institutional context and engineering wisdom.
Domain: SHIP
Get the work to customers
The Ship domain covers the last mile from merge-ready code to live product. For many teams, deployment infrastructure is already the most automated part of the lifecycle via existing CI/CD. The opportunity is extending that automation upstream into documentation, compliance tracking, and release coordination—which are often manual bottlenecks even when deployment itself is smooth.
Stage 7: Documentation & Release Readiness
Changes are documented and all release artifacts are prepared. Includes technical documentation, release notes, API documentation, internal knowledge base updates, compliance tracking of changes (audit trails, change control records), security impact documentation, and regulatory or customer-facing disclosures where applicable. For B2B SaaS companies serving regulated industries, traceability from ticket to deployed change is not optional.
Output: stakeholders know what changed and why, and all compliance and audit requirements are satisfied.
Agent-Ready vision: An agent generates documentation, release notes, changelog entries, and compliance records from the PR, commit history, and ticket context—ready for human review rather than human drafting. Audit trail generation is fully automated.
Stage 8: Deployment & Release
Code is shipped to production. Includes CI/CD pipeline execution, feature flagging, staged rollouts, and release coordination.
Output: the change is live and customers can use it.
Agent-Ready vision: Largely achieved through existing CI/CD. Future improvements include agent-triggered rollbacks based on anomaly detection, smarter feature flag management, and automated canary analysis.
Domain: LEARN
Measure impact and close the loop
The Learn domain closes the feedback loop from production back to problem discovery. This is the least automated domain at most organizations and represents the largest untapped opportunity. An agent that can synthesize production telemetry, customer adoption data, and support signals into actionable insights would fundamentally accelerate the entire cycle.
Stage 9: Observability & Production Intelligence
Production systems are observed and patterns are surfaced proactively. Includes distributed tracing, structured logging, metrics collection (via OpenTelemetry and similar standards), alerting, error correlation, performance monitoring, incident management, and trend analysis. The shift from reactive monitoring (“alert me when something breaks”) to proactive observability (“show me what’s happening and what’s changing”) is central to this stage.
Output: fast detection of problems, emerging patterns, and production insights that inform the next cycle.
Agent-Ready vision: An agent triages alerts, correlates errors with recent deployments, drafts incident summaries, performs initial root cause analysis, and creates investigation tickets—reducing mean time to detection and response. Proactive trend analysis surfaces degradation before customers notice.
Stage 10: Customer Value & Feedback Loop
Impact is measured and learning flows back into the cycle. Includes feature adoption tracking, usage analytics, customer value metrics (time saved, revenue impact, workflow efficiency), customer health scoring, support ticket analysis, NPS and satisfaction signals, and direct customer conversations. The emphasis is on measuring value delivery quantitatively—adoption and outcome data is the most automatable and highest-signal input for the next cycle, while human feedback remains critical for context and nuance.
Output: evidence of whether value was delivered and how customers are adopting changes, feeding directly back into Stage 1 prioritization.
Agent-Ready vision: An agent analyzes adoption metrics, support ticket patterns, and usage data to surface what’s working, what’s underperforming, and what customers are struggling with—closing the loop from delivery back to discovery with data, not anecdote.
How to Use This Model
The value of any framework is in its application. The Agent-Ready Maturity Model is designed to be practical—something a team can pick up, apply, and begin generating insight from in a single session. It works in three phases: assess, set goals, and measure progress.
Phase 1: Self-Assessment
The team scores their current state across all 10 stages using the 0–4 maturity scale. The assessment surfaces where teams feel friction, where automation has already taken hold, and where the biggest gaps exist between current state and potential.
Assessments should be honest, not aspirational. If a stage is manual, score it 0. If assistants are in use but humans still drive every decision, that’s a 1. The spider chart that results from an honest assessment is far more useful than an inflated one.
Phase 2: Goal Setting
Leadership establishes targets in collaboration with the team across three horizons: 6 months, 12 months, and 18 months. These targets should be set per stage, and goals should reflect where investment will have the highest impact—not a uniform push across all axes.
Good goal setting is harder than it looks. The temptation is to target the highest maturity level across every stage immediately. This leads to diffuse effort, slow progress on everything, and a sense that nothing is actually improving. The better approach is to focus. Pick 2–3 stages where a level transition would unlock the most downstream value, invest there deliberately, and achieve wins that are visible and real.
Visible progress builds momentum. A team that moves Testing from Level 1 to Level 2 and can demonstrate measurably faster validation cycles will be more motivated—and more credible—than a team that made marginal progress across eight stages simultaneously. Celebrate the wins. Let success fuel further ambition.
Goal setting should also consider dependencies between stages. For example, moving Implementation (Stage 4) from AI-Accelerated to Agent-Ready is difficult without first improving Work Decomposition (Stage 3), because agents need well-defined inputs to produce good outputs. The model reveals these dependencies; leadership should sequence goals accordingly.
Phase 3: Progress Measurement
Reassess at regular intervals, with cadence determined by the team’s rate of change. Teams in active improvement cycles should check in monthly. Teams in a steady state may assess quarterly. A reasonable starting cadence is quarterly full assessment with monthly check-ins on active focus areas.
Progress measurement should track two things: the maturity score itself (are we advancing levels?) and the friction indicators that the score reflects (are builds faster? are reviews less bottlenecked? are incidents resolved sooner?). The maturity score is the leading indicator; the operational improvement is the lagging confirmation that the score reflects real change.
Over time, the model becomes a shared language for discussing infrastructure investment. Instead of abstract debates about “should we invest in better testing?” the conversation becomes “we’re at Level 1 on Testing and our 6-month target is Level 2—what specifically is blocking that transition?”
Illustrative Assessment
The following spider chart and scorecard represent an illustrative baseline assessment with proposed targets. Current-state scores should be validated by teams as a kickoff exercise. Targets are intentionally conservative, focused on achievable progress in the highest-impact stages. The scores below are illustrative – your organization’s profile may look different.
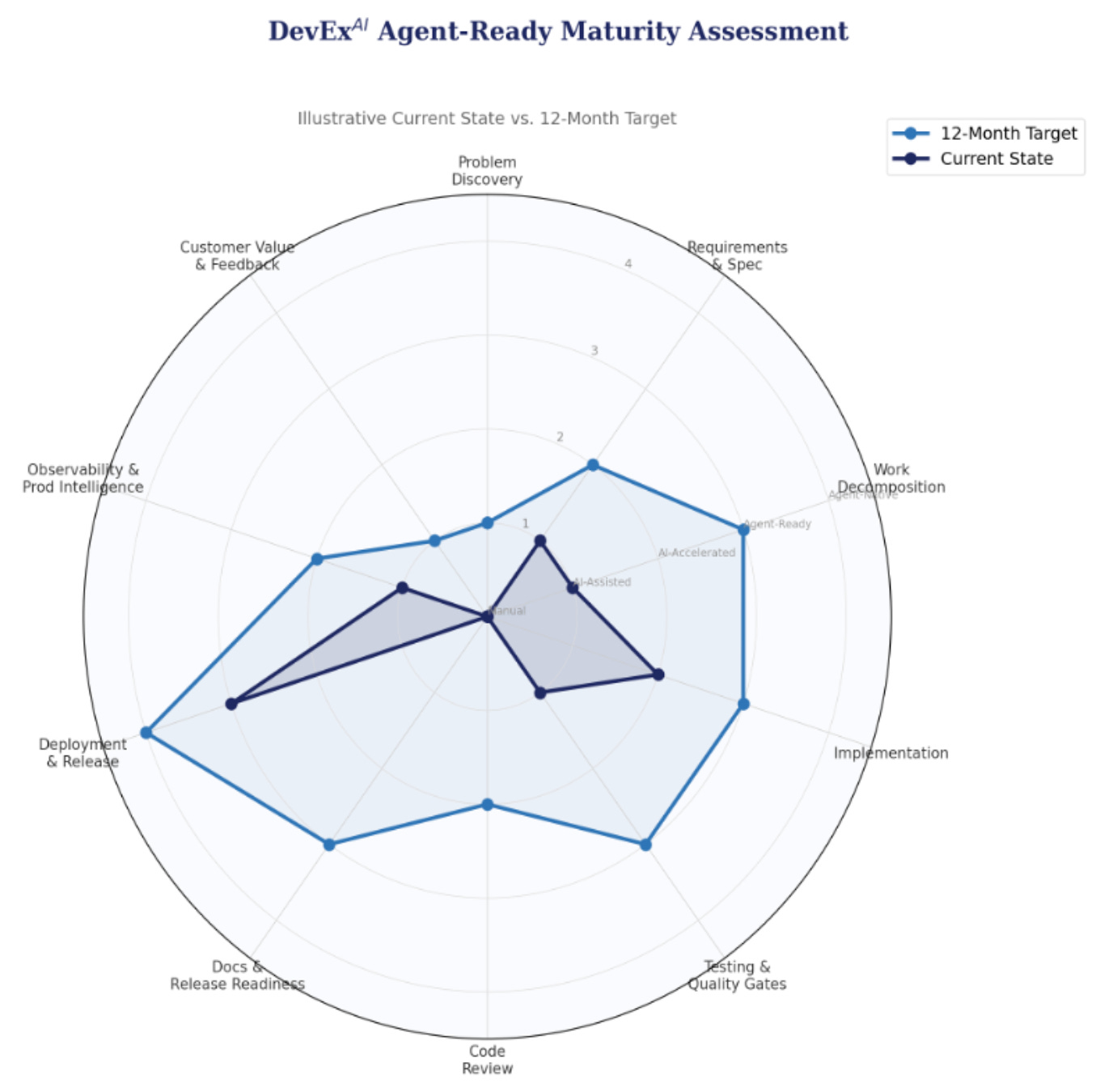
Figure 1: Sample Agent-Ready Maturity Assessment (illustrative scores)
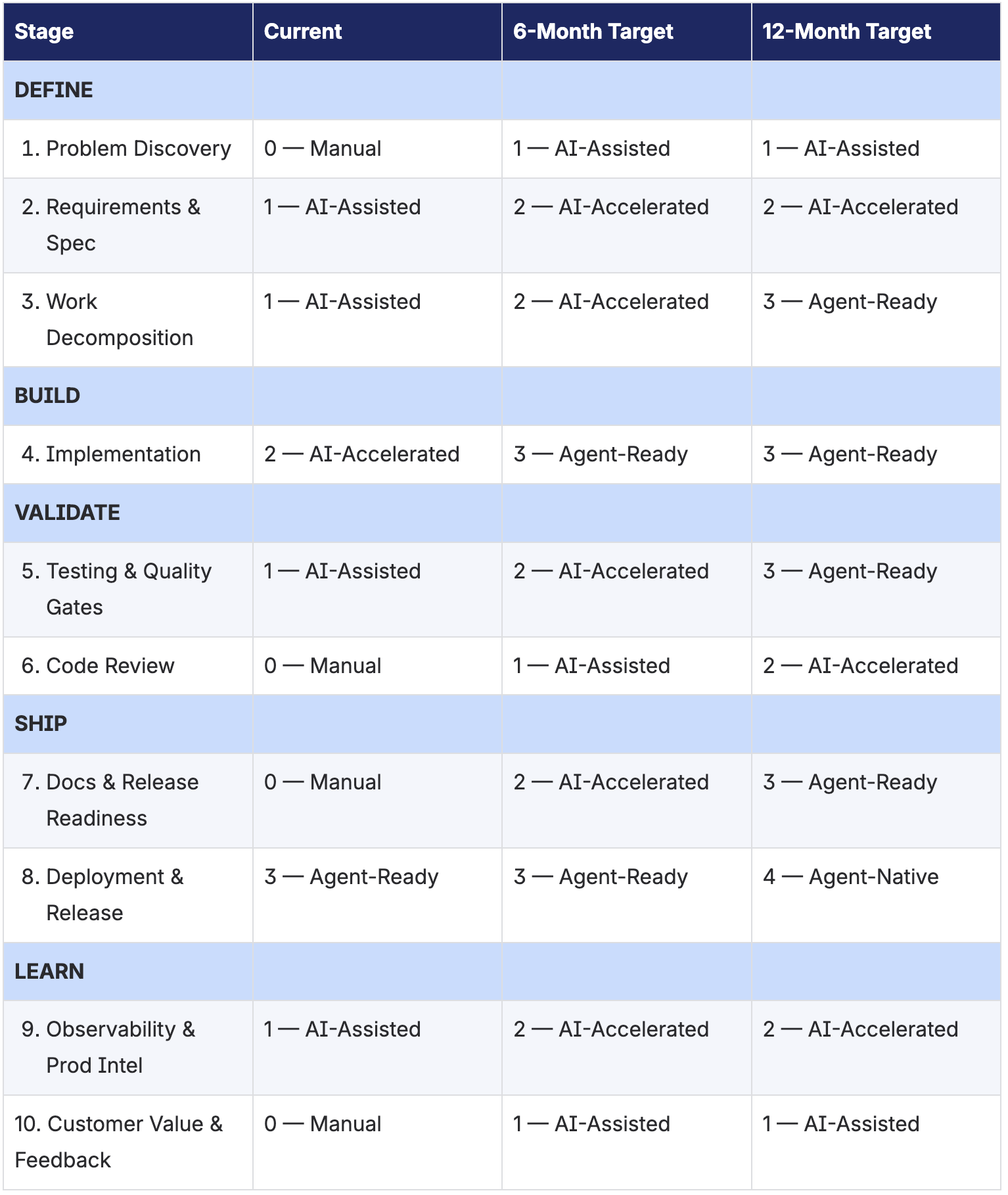
Table 1: Sample Agent-Ready Maturity Scorecard (illustrative scores)
Developer Experience as the Foundation
DevExAI is a framework about developers—not about agents. The “raised to the power of AI” formulation is intentional: the base is developer experience. AI is the exponent. Remove the base and the exponent is meaningless.
This distinction matters because it determines what success looks like. Success is not a dashboard full of Level 4 maturity scores. Success is engineers who spend more of their time on work that requires judgment, creativity, and institutional knowledge—and less time on mechanical toil that an agent could handle. The maturity model measures the infrastructure. The developer’s experience is the outcome that infrastructure serves.
The Value of Developer Experience
The Developer Experience (DevEx) discipline emerged from a simple but powerful insight: developer productivity is not determined primarily by individual talent or effort. It is determined by the friction and feedback loops in the environment around them. How long does it take to get a build? How clear are the requirements? How painful is the review process? How fast can you get feedback on whether your change works? These environmental factors compound across every engineer on a team, every day. Small reductions in friction produce outsized improvements in throughput, quality, and job satisfaction.
DevExAI does not replace this discipline. It builds on top of it. The agent-readiness lens adds a new dimension—asking not only “is this experience good for humans?” but “is this experience good for agents too?”—and in doing so often reveals friction that teams have normalized but never resolved. But the foundation remains: if you are not investing in developer experience, agent-readiness improvements will underperform because the environment they operate in is degraded for everyone.
Complementary Instruments
The Agent-Ready Maturity Model and traditional DevEx measurement are complementary instruments that reveal different things.
The maturity model asks: can an agent operate effectively at this stage? It measures infrastructure readiness—the presence of clear specs, automated tests, CI pipelines, observability tooling, and feedback mechanisms that agents need to function.
A DevEx survey asks: how does it actually feel to work here? It measures the human experience—perceived friction, satisfaction, confidence in tools, and the sense that the environment supports rather than hinders good work.
You need both signals. A stage can score well on agent-readiness while the human experience remains painful—the tooling is there but the workflow hasn’t adapted, or the agent output quality isn’t trusted enough to save time. Conversely, a team can report reasonable satisfaction with a stage they’ve normalized as manual, while the maturity model reveals enormous untapped potential. The most valuable insights emerge at the intersection: where maturity and satisfaction converge or diverge, that’s where leadership attention should focus.
Operational Metrics Still Matter
The Agent-Ready Maturity Model measures capability—what level of agent involvement is possible at each stage. It does not directly measure performance—how fast and how well the team is actually delivering. For that, you need operational metrics.
Cycle time, PR review time, deployment frequency, change failure rate, mean time to recovery—these well-established metrics remain essential. They are the lagging indicators that confirm whether agent-readiness improvements are translating into real delivery performance. Frameworks like DORA (developed by Nicole Forsgren, Jez Humble, and Gene Kim) and SPACE (developed by researchers at Microsoft Research and GitHub) provide structured approaches to measuring software delivery performance and developer productivity across multiple dimensions.
DevExAI intentionally does not replicate that ground. The DevEx and engineering metrics landscape is well-established and well-documented. What has been missing is a framework that maps agent-readiness specifically across each stage of the software lifecycle—and that is what the Agent-Ready Maturity Model provides. The three work together:
DevEx surveys tell you where developers feel friction and where the environment is supporting or hindering their work. Run these regularly—quarterly at minimum—and track trends over time.
Operational metrics tell you how the system is performing. Cycle time, PR throughput, deployment cadence, incident recovery—these confirm whether improvements are showing up in your delivery pipeline.
The Agent-Ready Maturity Model tells you where agent automation is possible, where it’s blocked, and where investment will have the greatest leverage. It is the leading indicator; DevEx surveys and operational metrics are the confirming evidence that maturity improvements are producing real outcomes.
The Role Evolves, the Principle Endures
Behind every maturity score is a team of people trying to do meaningful work. The purpose of this framework is not optimization for its own sake. It is to create an environment where engineers can focus on the problems that require their judgment, creativity, and experience, and where agents handle the rest. That is a better path for everyone involved.
As stages mature toward Agent-Ready and Agent-Native, the nature of the developer’s role will shift. from performing the work to directing and evaluating it. The DevEx questions evolve accordingly: from “how painful is this task?” to “how confident are you in the agent’s output?” and “how effective are the guardrails?” But the principle remains constant. The developer’s experience is the measure of success at every level, from Manual through Agent-Native.
The agents serve the humans. Not the other way around.
Foundations
No framework exists in isolation. DevExAI is built on the work of practitioners and researchers who have shaped how the industry thinks about software delivery, developer productivity, and the relationship between tools and the people who use them.
The DevOps movement established that software delivery is a whole-system problem. Nicole Forsgren, Jez Humble, and Gene Kim formalized this understanding through the DORA research program and their book Accelerate, demonstrating that software delivery performance — measured through deployment frequency, lead time, change failure rate, and mean time to recovery — directly predicts organizational performance. Gene Kim’s earlier work, including The Phoenix Project and The Unicorn Project, made the case that developer friction is an organizational problem, not an individual one.
Forsgren and colleagues extended this thinking through the SPACE framework in 2021, establishing that developer productivity cannot be captured by any single dimension. Abi Noda and the DevEx community built further, shifting the conversation from measuring productivity to improving the lived experience of developers — the friction, feedback loops, and environmental factors that determine whether engineers can do their best work.
Gergely Orosz at The Pragmatic Engineer has been the most consistent voice documenting the pragmatic reality of how AI is changing software engineering at established companies — separating what is genuinely working from what is hype, and showing how engineering roles are transforming rather than disappearing. Matt Biilmann at Netlify introduced the discipline of Agent Experience, recognizing that tools designed for humans often fail for agents and that designing for agent usability improves the experience for everyone.
To my knowledge, no existing framework maps agent-readiness specifically across each stage of the product development lifecycle. DORA and SPACE measure delivery performance and developer productivity. Existing AI adoption models measure organizational usage broadly. DevExAI is differentiated by its per-stage, SDLC-specific lens, asking not “how is our organization adopting AI” but “how agent-ready is each step of how we build software?”
Closing
DevExAI is built for practitioners. It is not a vendor framework or a product pitch. It is a practical tool for engineering teams navigating the next phase of how software is built; the phase where developers and agents work together across the full lifecycle, and where the friction removed drives the value created. The opportunity is real, the tools are here, and the teams that move with clarity and conviction will build better software for the people who depend on it.
References
Forsgren, N., Humble, J., Kim, G. Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations. IT Revolution Press, 2018.
Kim, G. The Unicorn Project: A Novel About Developers, Digital Disruption, and Thriving in the Age of Data. IT Revolution Press, 2019.
Forsgren, N., Storey, M-A., Maddila, C., Zimmermann, T., Houck, B., Butler, J. “The SPACE of Developer Productivity: There’s More to It Than You Think.” ACM Queue, Vol. 19, No. 1, pp. 20–48. February 2021.
Noda, A., Storey, M-A., Forsgren, N., Greiler, M. “DevEx: What Actually Drives Productivity.” ACM Queue, Vol. 21, No. 2, pp. 35–69. April 2023.
Orosz, G. The Pragmatic Engineer (newsletter). pragmaticengineer.com. Ongoing.
Biilmann, M. “Introducing AX: Why Agent Experience Matters.” Biilmann Blog, January 2025. biilmann.blog/articles/introducing-ax/